AIMET Model Compression¶
Overview¶
AIMET provides a model compression library that can be used to reduce a model’s MAC and memory costs with a minimal drop in accuracy. AIMET supports various compression schemes like Weight SVD, Spatial SVD and Channel Pruning.
Use Case¶
AIMET allows user to take a trained model and compress it to desired compression ratio which can be further fine-tuned and exported to a target. All of the compression schemes in AIMET use a two-step process - Compression ratio selection followed by model compression.
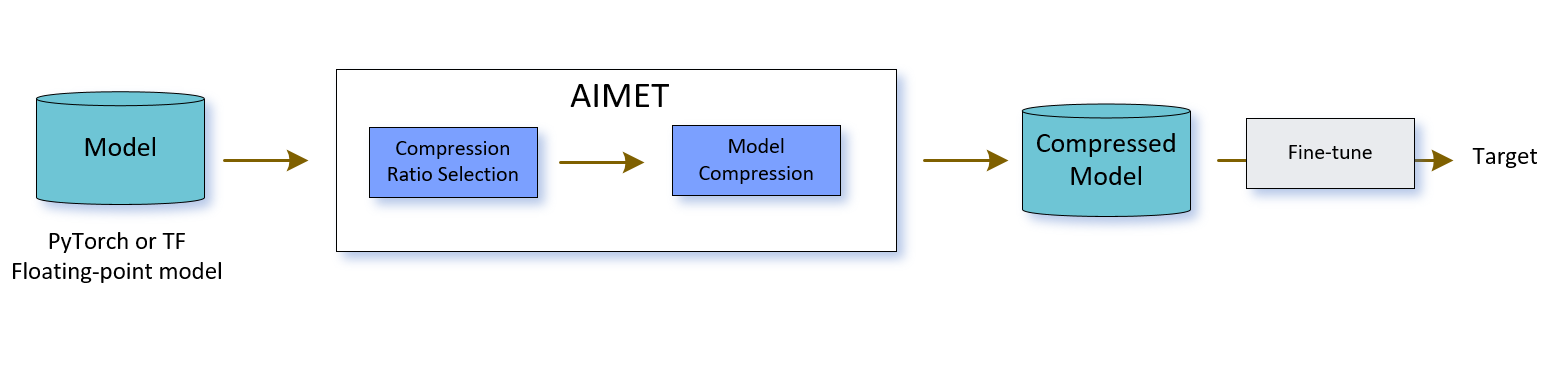
The following sub-sections explain these steps in more detail.
Compression ratio selection¶
Greedy Compression Ratio Selection: During this phase, individual layers of the original model are analyzed to determine optimal compression ratios per layer. Currently AIMET supports the Greedy Compression Ratio Selection method.
Manual Compression Ratio Selection: As an alternative to AIMET automatically selecting optimal compression ratios per layer, the user has a choice to specify compression ratios manually per layer. The suggested procedure would be to use the Greedy Compression Ratio Selection method to get a nominal set of compression ratios first. And then use this as the starting point for manually changing compression ratios for one or more layers.
To visualize various usage of the compression tool we can use:
Model Compression¶
In this phase, AIMET will apply the compression ratios per layer to create a compressed model. Currently, AIMET supports the following model compression algorithms.
Optional techniques to get better compression results¶
AIMET supports the following techniques that can be optionally used to get better compression results
Rank-rounding
Per-layer fine-tuning
Rank Rounding¶
Often ML runtime-software like those for Embedded ML accelerators, will prefer the dimensions of layers like Conv2d or FC to be of a certain multiplicity. Matching the expected dimension size will result in optimal runtime for that layer. AIMET techniques like Weight/Spatial SVD or Channel Pruning, try to decompose layers or reduce layers - specifically in terms of output channels and input channels. The rank-rounding feature in AIMET will try and reduce layers to match a user-provided multiplicity. By default this feature is disabled. At present, AIMET allows the user to specify a multiplicity-factor for the entire model, not on a per-layer basis.
Users can make use of this feature to generate more optimal models for running on embedded targets.
Per-layer Fine-tuning¶
Given a user-model and desired compression-ratio, the user may sometimes notice a sharp degradation in accuracy after compression but before fine-tuning. One technique that might help the overall compression of such scenarios, is using a feature called per-layer fine-tuning. When this feature is selected, AIMET invokes a user-provided fine-tuning function after compressing every layer that was selected for compression. This is done during the Model Compression phase in the diagram shown above.
Note: The user is responsible for choosing appropriate learning-rates and other training parameters for fine-tuning. Using this feature may require the user to carefully pick the learning rates and learning-rate-decay parameters to be used during fine-tuning.
FAQs¶
Which technique is the best technique to use for compression?
We see best results when Spatial SVD is performed followed by Channel Pruning.
Can we combine the different techniques?
Yes, as stated in 1, different techniques can be combined together to get better accuracy. Compression can be combined with Post-training Quantization techniques as well to get a better model for target.
How to take a model to target after compression?
To take a model to target it needs to be first compressed using the above techniques and then it should be quantized and exported to target
Greedy rank selection is very slow. Can something be done to speed it up?
Greedy rank selection in itself is not time consuming. The time consuming part is creating the eval-score dictionary. For different experiments, eval-score dictionary can be generated once and then loaded into the searcher. Or, one can reduce the number of candidates over which the eval-score dictionary is created. But lesser the number of candidates, lesser the granularity. To strike a balance the value of 10 candidates was chosen.
Is per-layer fine tuning helpful?
Per-layer fine tuning is an experimental technique. We have not observed major gains by using it. But one can try out if it works for their model. In practice, we have observed that the best combination is to do say 1 epoch of fine-tuning per-layer and then do say 10-15 epochs of fine-tuning for the entire compressed model at the end.
References¶
Xiangyu Zhang, Jianhua Zou, Kaiming He, and Jian Sun. “Accelerating Very Deep Convolutional Networks for Classification and Detection.” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 10, pp. 1943-1955, 1 Oct. 2016.
Yihui He, Xiangyu Zhang, and Jian Sun. “Channel Pruning for Accelerating Very Deep Neural Networks.” IEEE International Conference on Computer Vision (ICCV), Venice, 2017, pp. 1398-1406.
Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. “Speeding up Convolutional Neural Networks with Low Rank Expansions.” British Machine Vision Conference, Jan. 2014.
Andrey Kuzmin, Markus Nagel, Saurabh Pitre, Sandeep Pendyam, Tijmen Blankevoort, Max Welling. “Taxonomy and Evaluation of Structured Compression of Convolutional Neural Networks.”