AIMET: AI Model Efficiency Toolkit Documentation
AI Model Efficiency Toolkit (AIMET) provides tools enabling users to quantize and compress PyTorch models. Quantization is an essential step when deploying models to edge devices with fixed-point AI accelerators.
AIMET provides both post-training and fine-tuning techniques to minimize accuracy loss incurred when quantizing floating-point models.
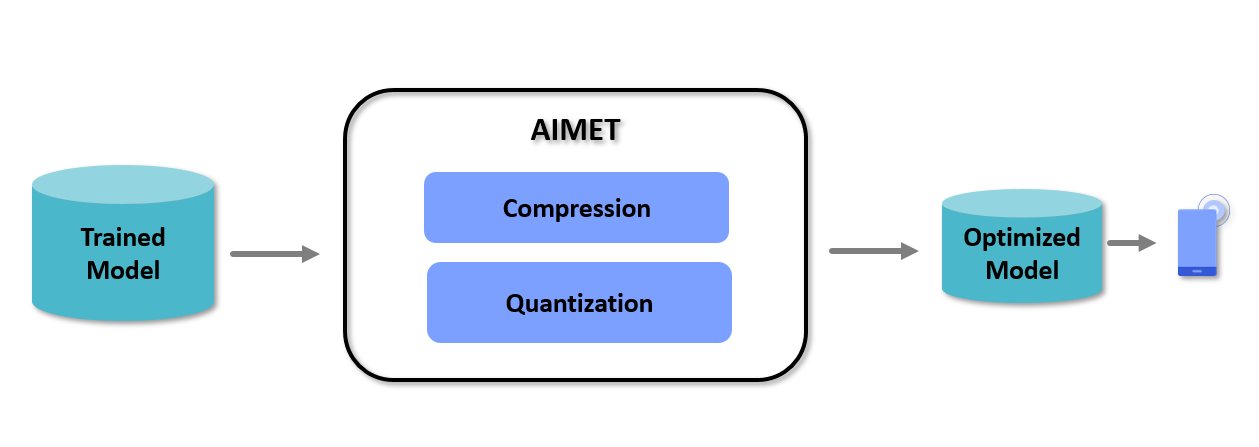
The above picture shows a high-level view of the workflow when using AIMET. The user passes a trained floating-point model to AIMET’s APIs for quantization. AIMET returns a new PyTorch model simulating low-precision inference, which users can fine-tune to recover lost accuracy. Users can then export the quantized model via ONNX/torchscript to an on-target runtime like Qualcomm® Neural Processing SDK.
Getting Started
Pip Installation:
apt-get install liblapacke
python3 -m pip install aimet-torch
For more installation options, please visit the AIMET installation instructions.
Basic Usage:
import aimet_torch.v2 as aimet
# Create quantization simulation model for your model
sim = aimet.quantsim.QuantizationSimModel(model, sample_input)
# Calibrate quantization encodings on sample data
with aimet.nn.compute_encodings(sim.model):
for data, _ in data_loader:
sim.model(data)
# Simulate quantized inference
sample_output = sim.model(sample_input)
# Export model and quantization encodings
sim.export("./out_dir", "quantized_model", sample_input)
Please view the Quickstart Guide for a more in-depth guide to using AIMET quantsim.
Examples
Feature Descriptions
AIMET PyTorch API