AIMET features¶
The end goal of the AI Model Efficiency Toolkit (AIMET) is to modify a trained floating point model to run with acceptable performance and accuracy on an edge device (the target device). The AIMET quantization process uses the following tools to achieve this goal.
Quantization simulation¶
Quantization simulation (QuantSim) uses quantization and dequantization (QDQ) operations to mimic quantized behavior on floating-point hardware. To do this, QuantSim adds QDQ nodes to an existing floating point model.
A QuantSim workflow is illustrated here:
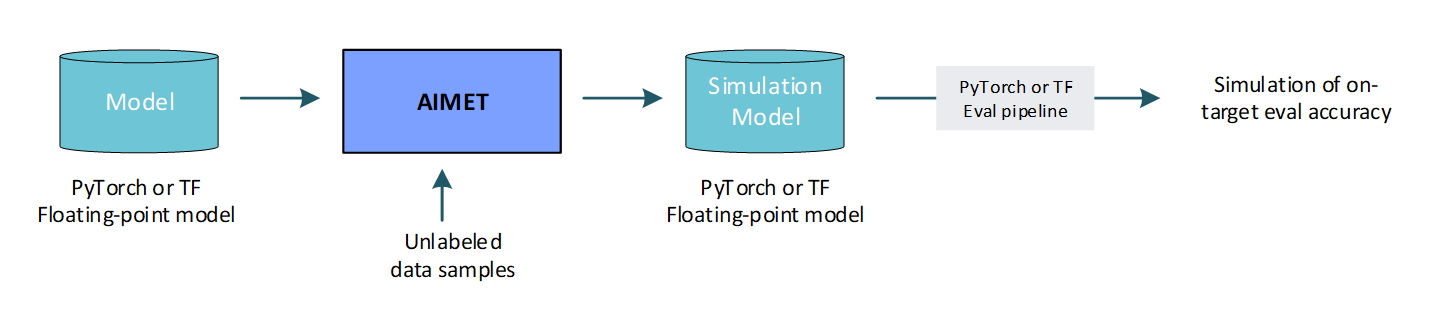
Quantization simulation is described in the Quantization simulation guide.
QuantSim saves development time by helping you estimate the accuracy of a quantized model without repeatedly deploying it to quantized hardware.
Accuracy improvement tools¶
Quantizing degrades a model’s accuracy. AIMET implements three types of techniques to restore accuracy to a quantized model:
Post-training quantization (PTQ)
Quantization-aware training (QAT)
Mixed precision
There are no one-size-fits-all rules to dictate in what order to try accuracy improvement techniques. In general, we recommend that for non-LLM models (or any model with fewer than billions of parameters) you try PTQ techniques first, as they require no fine-tuning and less engineering effort (PTQ doesn’t require you to set up and run a training pipeline).
Supported precisions for on-target inference¶
Before applying quantization techniques, identify the computational precisions supported by the target runtimes on which you plan to run inference. For weights and activations, the precisions supported by AIMET are: FP32, FP16, INT16, INT8, and INT4.
Some recent runtimes also support heterogeneous bit-width (also called mixed precision), enabling you to run sensitive operations at a higher precision within your model.
Precisions supported by AIMET for inference on target runtimes like Qualcomm® AI Engine Direct are:
Precision format |
Weights |
Activations |
|---|---|---|
Floating-point (No quantization) |
FP16 |
FP16 |
Integer (quantized W8A16) |
INT8 |
INT16 |
Integer (quantized W8A8) |
INT8 |
INT8 |
Integer (quantized W4A8) |
INT4 |
INT8 |
Post-training quantization¶
Post-training quantization (PTQ) techniques make a model more quantization-friendly without requiring model retraining or fine-tuning. PTQ is a preferred tool in the quantization workflow because it is efficient and easy to use and does not require model training.
The PTQ workflow is illustrated here:
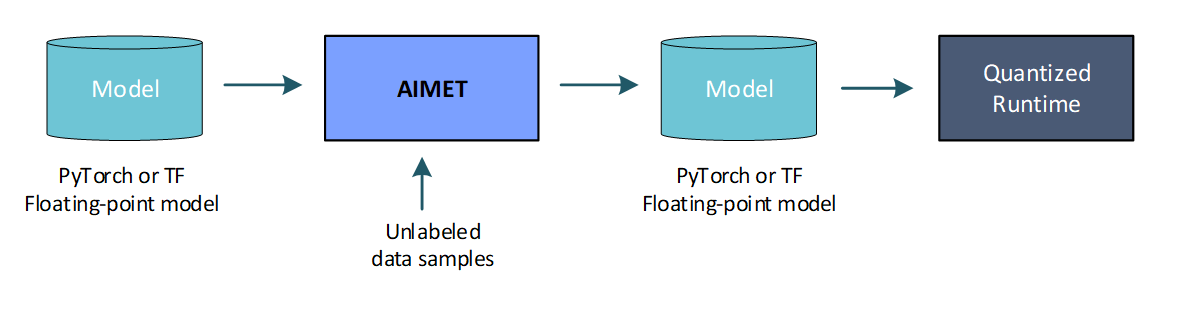
Post-training quantization techniques are among those described in Optimization techniques.
Quantization-aware training¶
Quatization-aware training (QAT) enables you to fine-tune a model with QDQ operations inserted in the model graph. In effect, QAT makes the model parameters robust to quantization noise.
Compared to PTQ:
QAT requires a training pipeline and dataset
QAT takes longer because it needs some training to fine-tune the quantized model
QAT requires hyper parameters search
However, QAT can provide better accuracy than PTQ, especially at lower bit-widths.
A typical QAT workflow is illustrated here:
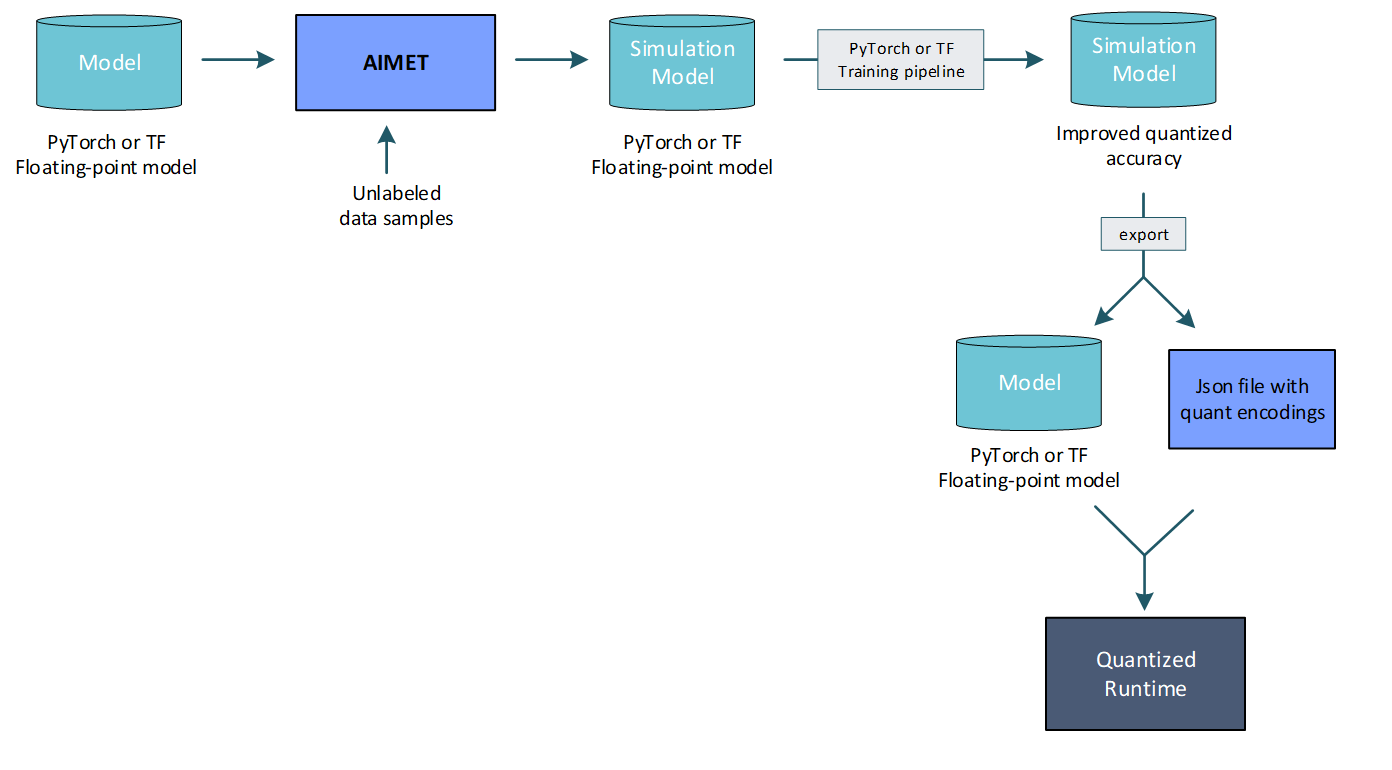
Quantization-aware training is described in Quantization aware training.
Mixed precision¶
AIMET’s mixed precision tools help you identify sensitive layers in the model and run these layers at higher precisions, achieving higher accuracy with a smaller model.
Mixed precision in AIMET follows the following steps,
Create the QuantSim object with a base precision
Set the model to run in mixed precision by changing the bitwidth of relevant activation and param quantizers
Calibrate and simulate the accuracy of the mixed precision model
Export the artifacts which can be used by backend tools like QNN to run the model in mixed precision
Mixed precision tools and techniques are described in Mixed precision.
Export tools¶
Once a simulated quatized model has recovered sufficient accuracy in QuantSim, it must be installed on a target device to test performance (and for final deployment, once performance is deemed adequate). AIMET provides an export API to generate the device-ready model.
And finally, you load the exported quantized model onto a target device. Qualcomm provides two paths to do this: Qualcomm® AI Hub, a cloud based lab; and Qualcomm® AI Engine Direct SDK for deploying directly to your own devices.
While not a part of AIMET, these paths – especially Qualcomm® AI Hub – provide a convenient way to implement a load-and-run cycle to test inference performance on a target device.
Export API¶
AIMET provides an API for exporting a QuantSim model to a device-runnable quantized model. The API generates the quantized model and a JSON-formatted encodings file containing the min, max, scale, and offset parameters of the QuantSim model’s quantizer nodes.
Deployment paths¶
- Qualcomm® AI Hub
Lets you deploy a model on a any of a number of Qualcomm chipset devices in a managed lab in the cloud. Behind the scenes, Qualcomm® AI Hub uses the Qualcomm® AI Engine Direct SDK to load your model.
- Qualcomm® AI Engine Direct SDK
A toolkit for deploying a model to your own device.