AI Model Efficiency Toolkit User Guide
Overview
AI Model Efficiency Toolkit (AIMET) is a software toolkit that enables users to quantize and compress models. Quantization is a must for efficient edge inference using fixed-point AI accelerators.
AIMET optimizes pre-trained models (for example, FP32 trained models) using post-training and fine-tuning techniques that minimize accuracy loss incurred during quantization or compression.
AIMET supports PyTorch, TensorFlow, and Keras models.
The following diagram shows a high-level view of the AIMET workflow.
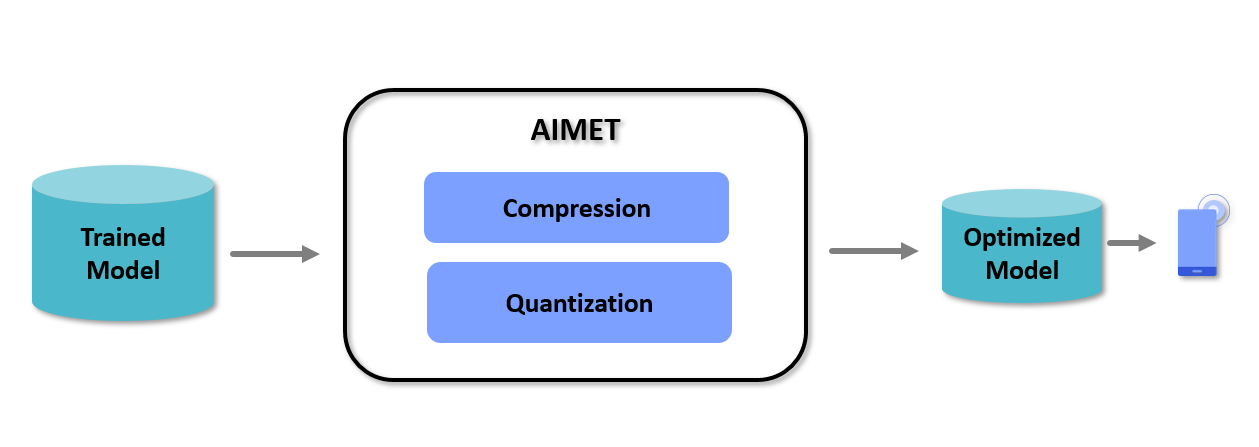
You train a model in the PyTorch, TensorFlow, or Keras training framework, then pass the model to AIMET, using its APIs for compression and quantization. AIMET returns a compressed and/or quantized version of the model that you can fine-tune (or train further for a small number of epochs) to recover lost accuracy. You can then export the model using ONNX, meta/checkpoint, or h5 to an on-target runtime like the Qualcomm® Neural Processing SDK.
Features
AIMET supports two model optimization techniques:
- Model Quantization
AIMET can simulate the behavior of quantized hardware for a trained model. This model can be optimized using Post-Training Quantization (PTQ) and Quantization Aware Training (QAT) fine-tuning techniques.
- Model Compression
AIMET supports multiple model compression techniques that remove redundancies from a trained model, resulting in a smaller model that runs faster on target.
More Information
For more information about AIMET, see the following documentation:
Release Information
For information specific to this release, see Release Notes and Known Issues.