AIMET model compression
Overview
AIMET provides a model compression library that can reduce a model’s multiply-and-accumulate (MAC) and memory costs with little loss of accuracy. AIMET supports various compression schemes like weight singular value decomposition (SVD), spatial SVD, and channel pruning.
See the Compression Guidebook for a summary of how to use the compression features, and how to combine them.
Use Case
AIMET can compress a trained model to a specified compression ratio. The model can then be further fine-tuned and exported to a target.
All of the compression schemes in AIMET use a two-phase process:
Compression ratio selection
Model compression
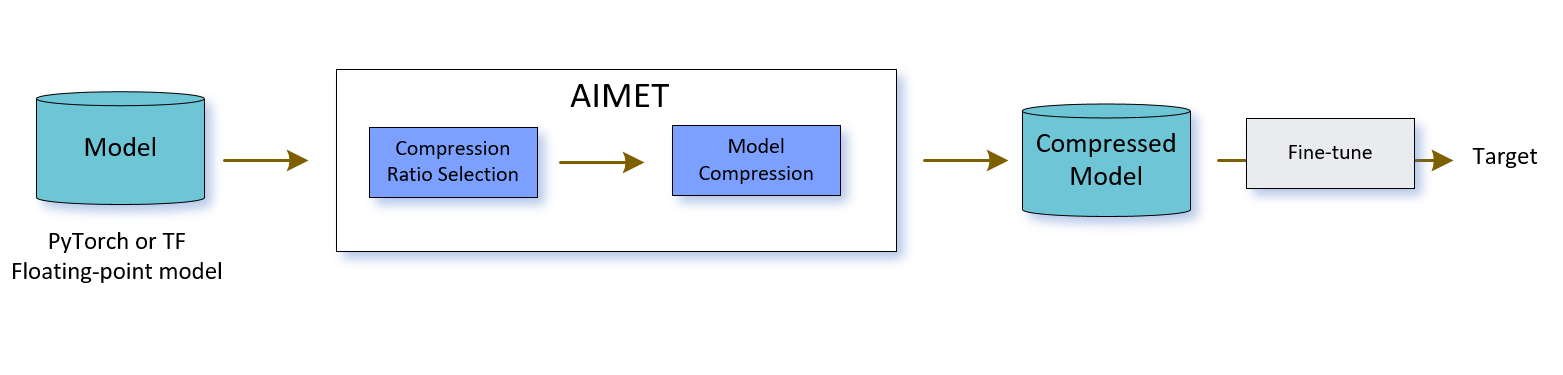
Both of these phases are explained below.
Compression ratio selection
In this phase, you select compression ratios automatically and/or manually. You can use AIMET Visualization to inspect these choices.
- Automatic compression ratio selection
AIMET computes optimal compression ratios for each layer, using the Greedy Compression Ratio Selection method for automatic compression.
- Manual compression ratio selection
You can manually specify compression ratios by layer. We suggest that you first use automatic compression ratio selection to get a baseline set of compression ratios, then manually change compression ratios for one or more layers.
- Visualization
Visualize compression as you apply these steps using AIMET Visualization.
Model compression
In this phase, AIMET applies the compression ratios to each layer to create a compressed model. AIMET supports the following model compression algorithms:
Optional techniques
AIMET supports the following optional techniques that can improve compression results.
Rank-rounding
Per-layer fine-tuning
Rank Rounding
AIMET techniques like weight SVD, spatial SVD, and channel pruning decompose or reduce input and output channel layers.
Certain types of layers (such as 2D convolution (Conv2D) or fully connected (FC)) in embedded ML accelerators are often optimized for certain multiplicities. Matching the expected multiplicity gives optimal runtime performance for that layer.
The rank-rounding feature in AIMET tries to reduce layers to match a user-provided multiplicity. AIMET only allows you to specify a multiplicity factor for the entire model, not per layer. Use this feature to optimize models to run on embedded targets. By default the feature is disabled.
Per-layer fine-tuning
For a given user model and compression ratio, compression sometimes causes a sharp drop in accuracy before fine-tuning. Per-layer fine-tuning is a technique that can help maintain model accuracy for desired compression ratios.
In this feature, AIMET invokes a user-provided fine-tuning function after compressing every layer that was selected for compression. This fine tuning is done during the model compression phase described above.
NOTE
This feature may require careful selection of learning rates and learning-rate-decay parameters to be used during fine-tuning. You are responsible for choosing these training parameters.
FAQs
Which is the best technique to use for compression?
We see best results when Spatial SVD is performed followed by Channel Pruning.
Can I combine the different techniques?
Yes, different techniques can be combined to get better accuracy. Compression can be also combined with post-training quantization techniques to get a better model for target.
How do I take a model to target after compression?
First, compress the model using the techniques described above. Then, quantize the model and export it to target.
Greedy rank selection is very slow. Can something be done to speed it up?
The time-consuming part is creating the eval-score dictionary, not greedy rank selection itself. A single eval-score dictionary can be generated once and then loaded into the searcher for different experiments. Or, reduce the number of candidates over which the eval-score dictionary is created, but be aware that the fewer candidates, the worse the granularity. The default value of 10 candidates usually strikes a good balance.
Is per-layer fine tuning helpful?
Per-layer fine tuning is an experimental technique. We have not observed major gains by using it. But, you can try it to see if it works for your model. In practice, the best results seem to come from doing one epoch of fine-tuning per layer, and then doing 10-15 epochs of fine-tuning for the entire compressed model at the end.
References
Xiangyu Zhang, Jianhua Zou, Kaiming He, and Jian Sun. “Accelerating Very Deep Convolutional Networks for Classification and Detection.” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 38, no. 10, pp. 1943-1955, 1 Oct. 2016.
Yihui He, Xiangyu Zhang, and Jian Sun. “Channel Pruning for Accelerating Very Deep Neural Networks.” IEEE International Conference on Computer Vision (ICCV), Venice, 2017, pp. 1398-1406.
Max Jaderberg, Andrea Vedaldi, and Andrew Zisserman. “Speeding up Convolutional Neural Networks with Low Rank Expansions.” British Machine Vision Conference, Jan. 2014.
Andrey Kuzmin, Markus Nagel, Saurabh Pitre, Sandeep Pendyam, Tijmen Blankevoort, Max Welling. “Taxonomy and Evaluation of Structured Compression of Convolutional Neural Networks.”